全国服务咨询热线:
13645227925
13645227925
采集矿石样本高光谱图像
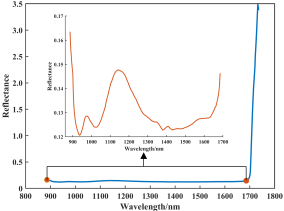
图1b(蓝色线条)为HSI捕获到的原始平均光谱曲线,可以明显看到在整个光谱区域没有特异的波峰波谷。为了找出峰谷突出的区域,分析了光谱波段之间的相关性。
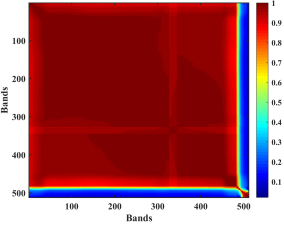
对于维度为(x, y, λ)的高光谱数据,转换为(z = x × y, λ),并对z进行相关性分析,结果如a所示。
图中显示红色区域的波段在整个波段中占比94.34%,其余颜色区域总共占比5.66%。为了最大限度地保留 “纯净数据",防止其它颜色区域数据的干扰,
通过查询颜色栏数据并结合波段得知红色与其余颜色区域的相关性分界点为0.8(波段:483)。随后,将相关性小于0.8的98个波段从数据分析中剔除,
从而消除了1685.47-1735.34 nm的光谱区域。得到的光谱曲线如图1b(红线)所示。该过程获得的光谱数据(150×483)用于后续的模型建立和分析。
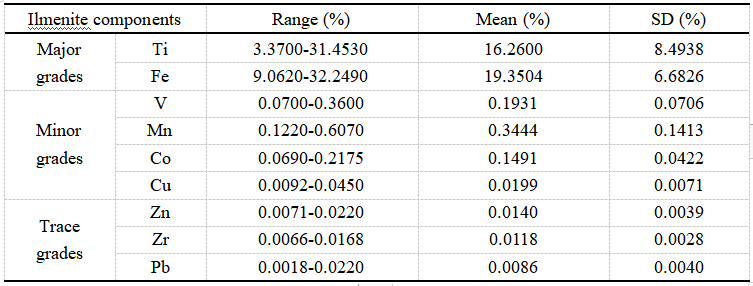
检测出了钛铁矿中品位较高的9种金属元素,根据其品位高低对样本进行分组。
其中,1%及以上为主要品位(Ti, Fe),0.02-1%为次要品位(V, Mn, Co, Cu),0.02%及以下为微量品位(Zn, Zr, Pb)。
钛铁矿中各组分品位的统计分布如表1所示,可以清晰看出,不同组分的品位有明显的差异,这对回归模型的建立至关重要。
钛铁矿样本的光谱反射率值在0.03 - 0.27之间,证实粉状钛铁矿的整体反射率较低,并随品位的增加而降低。图1b显示在NIR区域,
该钛铁矿的光谱特征分别在940nm、1020nm和1300~1650nm处出现了波谷。具体地,光谱反射率值在940 nm处达到谷值,随后急剧下降,
这主要归因于O-Ti-O的拉伸和变形。该钛铁矿较宽的吸收波段主要位于1300 ~ 1650 nm,Izawa指出这是由八面体配位的亚铁在此附近产生晶体场跃迁分裂而引起的。
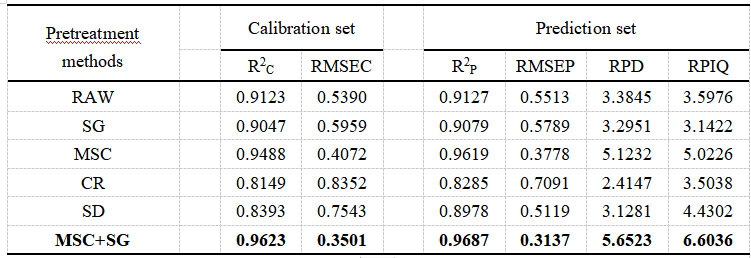
采用SavitZky一Golay卷积平滑法(简称SG平滑算法)、多元散射校正算法、包络线去除算法、二阶导数算法、多元散射校正+SG平滑算法等5种预处理方法对原始光谱数据进行处理。基于树突网络模型对比原始光谱数据,探索出HSI光谱数据的最佳预处理方法,结果如表2所示。预测集中,与原始数据相比,MSC+SG方法下的各指标R2P提高了5.88%,RMSEP降低了34.39%,RPD和RPIQ分别提高了28.86%和38.93%。
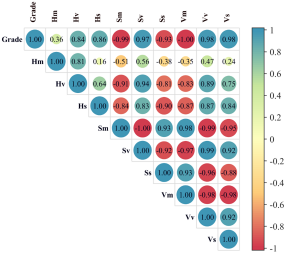
提取矿石样本的颜色特征是否可以用于构建品位预测模型,还有待进一步验证。基于钛铁矿多组分品位(平均品位)与颜色特征参数进行Pearson相关性分析。
从图中可以看出,除S颜色通道的特征参数与多组分品位存在弱相关(R < 0.3)外,其余颜色特征参数对于品位预测模型都是合理的。造成这种现象的原因是,
钛铁矿本身是一种不透明矿物,而HSI采集到的图像过于单一,整体颜色偏暗。
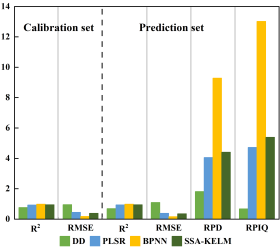
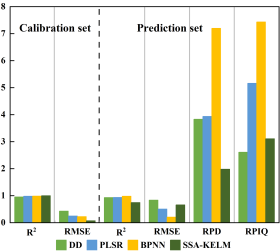
多元回归模型DD、PLSR和SSA-KELM可能对两个维度中某一特定数据集的表现最好,但基于多组分品位模型稳定性的需求,
BPNN才是最佳的模型选择。图5为基于BPNN两个的光谱和图像数据结果,可以看出,两个数据的指标变化差异不大,
证实了BPNN模型即使在小样本量下也具有很强的泛化性能和鲁棒性。综合评价表明,BPNN对两组数据集的预测都是成功的,
但利用图像数据预测钛铁矿多组分品位的可靠性略低于利用特征选择的光谱数据。
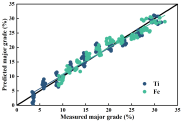
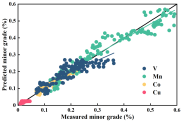
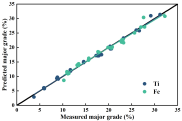
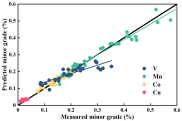
从iPLS-VCPA-IRIV特征选择的拟合光谱数据图可以看出,在校正集中,钛铁矿多组分品位都均匀准确地分布在理想曲线上。
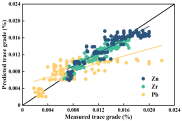
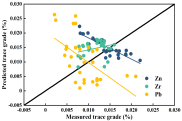
然而,对于预测集来说,明显可以看出来的是,除拟合良好的主要品位(Ti、Fe)
和次要品位(V、Mn、Co、Cu)外,微量品位(Zn、Zr、Pb)的拟合似乎并不令人满意。因此,在下一步工作中,
可以对少样本量下矿石内部微量品位的变化进行更深入的研究。
从光谱和空间维度出发,探讨了计量学相结合预测钛铁矿多组分品位的能力。
电话
微信
